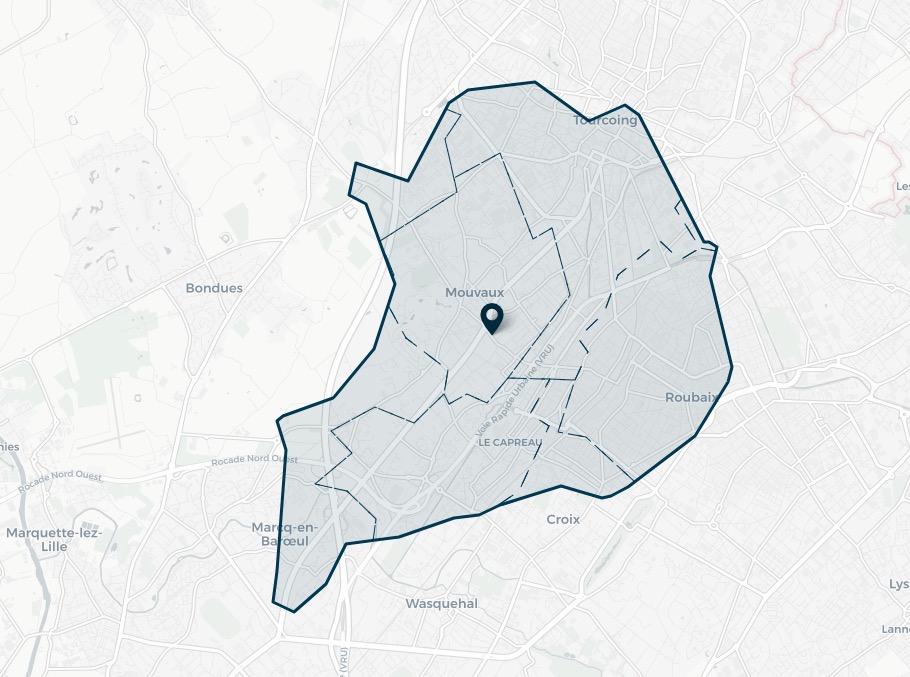
Vous vous demandez certainement ce qu’est une zone de chalandise et c’est normal. L’explication la plus simple est celle de la zone dans laquelle se trouve potentiellement vos clients. Cette zone de chalandise se définie le plus souvent en fonction de plusieurs paramètres qui sont le mode de transport et le temps de parcours. On parle dans ce cas d’un calcul d’isochrone.
Calculer à la main ce type de zone de chalandise n’est pas trivial car il faut prendre en compte le réseau routier et plein de paramètres comme la vitesse des routes, etc… Le plus souvent les entreprises qui utilisent les isochrones s’appuient sur des outils dédiés à cette tâche, malheureusement ces outils sont couteux et pas souvent ergonomique, de ce fait bon nombre d’entreprises n’utilisent pas ces zones de chalandise isochrone et c’est dommage car elles passent à côté d’une mine d’information.
La zone de chalandise toute seule c’est bien c’est visuel, c’est beau vous pouvez épater votre directeur mais une fois l’effet wahou il faut aller plus loin pour prendre des décisions. L’idéal est d’utiliser cette zone de chalandise pour filtrer de l’information externe et interne afin de pouvoir analyser précisément votre zone.